
Do you know the overfitting (overfitting) that you face once in machine learning?
Overfitting can have a negative impact on the model you want to predict. So how can we prevent overfitting?
This article introduces what overfitting is, its causes, countermeasures, etc. from specific examples.
What is overfitting in machine learning?
Overfitting “Alias: Overfitting” is one of the most common problems in data analysis.
Over-learning is a result of the computer learning too much training data prepared in advance when performing machine learning, and as a result, it is too fit for the training data and is fit for unknown data (test data). It refers to the state where there is no (no versatility).
This expression may be a little difficult to understand, so let’s replace it with something familiar and give an easy-to-understand example.
“School test”Please imagine.As a test measure before the test“Past question”I think I will solve it. Mr. A is solving only similar past questions with this test preparation,I only remember the combination of “questions” and “answers”, and when I took the actual test, I mightn’t solve all the new questions that hadn’t been asked in the past.Suppose there is a situation like this. This is the so-called overfitting state.
▼ Related articles
・ What is a model in machine learning? | About the types of models and what is a “good model”
・ What are the features and their selection methods that are indispensable for machine learning?
Specific examples of overfitting that occurs in machine learning
So what kind of model will be created if overfitting occurs?
Let’s look at three things: (1) lack of learning, (2) appropriateness, and (3) overfitting.
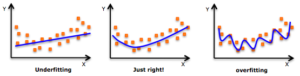
From the left, this graph is lined up with (1) insufficient learning, (2) appropriate, and (3) overfitting.
At first glance, the graph on the right seems to be in line with the most given data, but this is an overfitted model and overfitted.
If this happens, the machine learning model will be completely useless, so immediate action is required.
- Lack of learning: No model complexity, just capture the characteristics of the training data
- appropriate: Fully capture the characteristics of training data
- Overfitting: Overfitting to training data and not generalized to unknown data
Three main causes of overfitting in machine learning
Overfitting is one of the most common problems in data analysis and is a nuisance for data scientists. Why is it that even if we know the existence of overfitting, we cannot avoid overfitting and cause it? I will introduce three main causes.
- Lack of training data
- Biased data learning
- The purpose of the machine learning model you want to create is unclear
① Insufficient training data
One of the major causes of overfitting is the lack of training data.
When you hear overfitting, it is easy to misunderstand that you have learned too much (there is a lot of data).In fact, the lack of data hinders normal learning.
Even if a new job is assigned, human beings can respond to some extent from their experience and common sense in addition to the necessary data and can proceed with learning efficiently, but machine learning is the data obtained at the time of training. Is all.
in short,If the amount of data given is small, we can only analyze from that small amount of data and only deal with biased data.
Therefore, in order to realize correct data analysis, it is necessary to secure and train a sufficient amount of data according to the purpose.
② Learning of biased data
Another important thing to keep in mind when training data is to train biased data.
As mentioned in (1), analysis can only be performed from data given machine learning. for that reason,In order to perform a flat analysis, it is necessary to train abundant data with as little bias as possible.
If you train only biased data, such as building a model with insufficient data or learning only convenient data, the machine learning model lacks objectivity and can only perform biased analysis and prediction. , Will adversely affect the model construction itself.
In order to perform correct data analysis, prepare correct and abundant data.
③ The purpose of the machine learning model you want to create is unclear
As a preliminary step to building a model, the purpose of “what kind of model should be built?” Is absolutely necessary.
Not limited to machine learning, AI basically has only practicality specialized for single task, and it is not possible to execute various tasks from one data for general purposes, so let’s control it on the human side. Must be.
Do you want to predict store sales or population growth?If you build a model while it is unclear what you want to do, it will cause you to learn unnecessary data or biased data.
Build a “model that predicts store sales”. If the purpose is clarified, such as, it is possible to collect and learn a wide range of data necessary for the prediction.
Therefore, overfitting can be prevented by clarifying the purpose of what kind of model to build and training the appropriate data.
What to do to notice overfitting
In the unlikely event that you fall into overfitting, you need to be aware of it immediately and improve your model.
Even if you proceed with learning and prediction without noticing overfitting, only meaningless models and meaningless data will be born.
“Building a meaningless model-> calculating meaningless predicted values”It is important to follow the process of “model construction-> verification-> improvement-> model upgrade” so that this does not happen.
And, as introduced in the cause of overfitting, it is necessary to prepare sufficient data in advance without bias. once more,Separate and distinguish training data, verification data, and test data in advance.This will not bother you when assessing the accuracy of your model.
Such overfitting“bias”When“Variance”It is better to know because it has a deep relationship and is an important idea.
- bias: Difference between predicted result and measured value
- Variance: Variation of prediction result
fundamentally,Bias and variance are in a trade-off relationship, so how to balance them is very important.
A low bias is a good model for making predictions, but if the bias is too low, it will also adapt to noise (obstructive data that is originally ignored), resulting in large variations in prediction results. As a result, the variance increases. In addition, even if you try to adapt a complicated model to various data, the predicted values will vary and the variance will increase.
The tendency is that low bias and high variance are likely to be overfitting and should be observed carefully.
3 methods to prevent overfitting in machine learning
Even if you know the cause of overfitting and are careful, there is a good chance that it will cause overfitting.
So how can we avoid overfitting?
Here are three techniques to prevent overfitting.
① Hold-out method
The holdout method is one of the data testing methods in machine learning and is the simplest method of model evaluation.
In the holdout method, the accuracy of the trained model is evaluated by dividing it into training data (x_train, y_train) that creates a model from all the data sets and test data (x_test, y_test) that evaluates the model.
If you have 100 data, divide it randomly such as 6: 4 or 7: 3, divide it into 60 training data, 40 test data, and so on. (Many people allocate less test data)
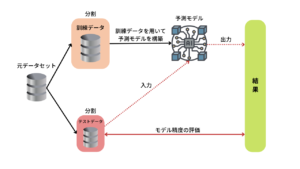
Created by AINOW editorial department
By constructing a model by dividing the data in this way, it is possible to improve the performance (generalization performance) for unknown data, and it is possible to create a model in which overfitting is unlikely to occur, but the original data ( If the number of samples) is small, the disadvantage is that the evaluation values will vary.
② Cross-validation
The cross-validation method is one of the methods for dividing training data and test data (validation data) like the holdout method, but the model is constructed by a slightly different division method from the holdout method.
Here, we will introduce K-folded cross-validation, which is often used in cross-validation.
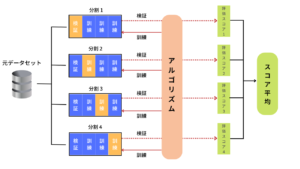
Created by AINOW editorial department
The K-validation method randomly divides the original data into k datasets. Build a model using one of the k divided datasets as test data and the rest as training data.
Then, all the divided data sets are sequentially verified as test data.A more reliable evaluation method than repeating the holdout method k times because there is no duplication between the datasets to be verified.However, it has the disadvantage that if the amount of data is enormous, such as 100,000 or more, the CPU will be overloaded and the calculation will take time due to the execution of k divisions and verifications.
③ Regularization (min-max normalization)
Normalization is a method of making a model that has become complicated due to overfitting into a simpler model, and is one of the highly versatile overfitting countermeasure methods that can also be used in analysis methods such as regression and classification.
The model is simplified by penalizing complex data and non-smooth models from the prepared data to reduce the weight, and ignoring isolated data.
(In the field of machine learning, ingenuity for improving overfitting is generally called normalization.)
There are two methods of normalization, each of which is used according to the purpose.
- L1 normalization: Clarify the required explanatory variables (set the effect of unnecessary explanatory variables to 0)
- L2 regularization: Smooth the predictive model (reduce the impact of complicating the model)
There are the following methods to use properly.
| When the number of data & explanatory variables is also large | Use L1 normalization to reduce the number of explanatory variables |
| When the number of data & explanatory variables is not large | Optimize the partial regression coefficient using L2 normalization |
Normalization is explained in detail in Qiita, so if you want to know more, please check it. (Qiita article:Why Machine Learning Needs Normalization)
▼ Related articles
・13 Machine Learning Techniques-Explanation for Beginners and Intermediates!
・ What is SVM (Support Vector Machine)? | Mechanism / Advantages / Study method
・ Reduce waste with accurate predictions! Summary of use cases of AI prediction
summary
What did you think.
In this article, we have introduced “overfitting” in machine learning.
When performing data analysis using machine learning, overfitting is inherent, so it is necessary to take appropriate measures.
In addition to the holdout method, cross-validation, normalization, and methods not introduced this time, there are solid measures to prevent overfitting, so when dealing with data in machine learning, use the method that suits your purpose and be accurate. Let’s create a high-quality model!
Tokyo International Technical College student, majoring in IoT systems.
While looking for something that looks interesting, I occasionally make IoT devices and play with them.
I want to disseminate information while looking for things that look interesting.

